Wouldn't it be nice if just by uploading images and videos to your media library the AI-assisted DAM system would automatically categorise and tag them and make them searchable?
So why is computer vision, despite major development steps, still not relevant in media bank workflows in 2022?
Amazing technology presented already 5 years ago
Back in 2016, I uploaded some images into a service during a presentation on the DAM Helsinki 2016 conference, and it showed these amazing tagging results then. The audience replied with applause and were impressed on how live tagging could be presented.
The service I used back then was called EyeEm Vision. EyeEm is one of the world’s leading photography marketplaces and communities with more than 20 million users. Using computer vision technology and facial recognition, the software tags photographs and video as they are imported.
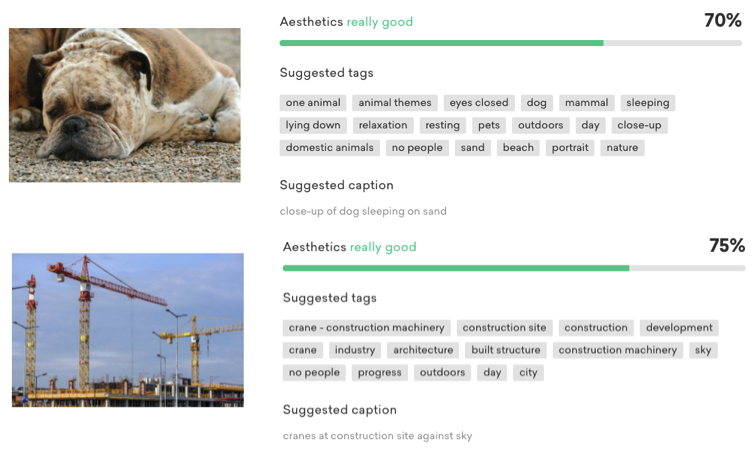
The resulting tags of my images were divided into not only keywords, but amazingly also by aesthetics and descriptions, or captions, if you prefer. EyeEm Vision, used a deep learning computer vision framework that attempts to identify and rank images by aesthetics and concept.
Caption results from the images, like "close-up of dog sleeping on sand" and "crane at construction site against sky" includes more information than what todays cloud based out-of-the box image regognition keywording in DAM deliver, not to mention adding the aesthetic value to the image.
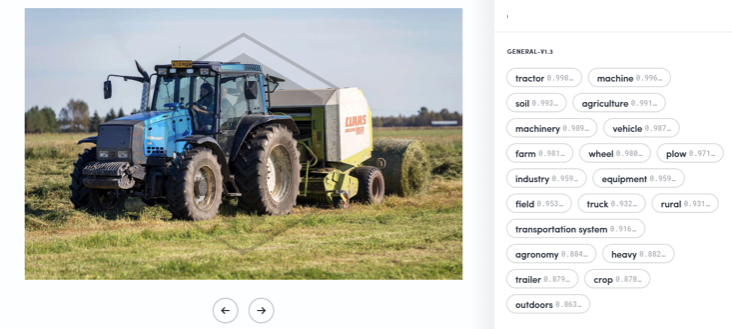
Often a successful keywording in DAM look like this tagging (Clarifai) result from any cloud image recognition provider, like Google Vision, Amazon Rekognition, Azure Cognitive Services, Imagga and Clarifai, among several others.
Making assets alive and searchable in DAM
Media Libraries are filled with unstructured data (images, videos etc). This content gets organised and classified by taxonomies, keywords and tags called metadata (data about data). But where is all that metadata coming from?

Adding metadata to digital assets is the trick that makes the digital assets searchable, findable, reusable and potentially repurposable, giving them more value. In this respect, a DAM solution is only as good as its metadata. Metadata really matters, although it can get cumbersome to fill the needed data.
Each piece of metadata is captured in a separate field, and a system of fields is called a metadata schema. For metadata to be effective, it must be applied consistently and accurately to every asset in a DAM system. Tagging files is the 2nd step after importing or cataloging your files, but arguable more valuable.
If you load something with no information you’re not doing anything better than you did before by sticking it in a folder on a server, in Dropbox or OneDrive. The best video in the world is of no use if it’s impossible to find! The beauty of digital asset management is the ability to add metadata that adds value to that digital asset and increases its retrievability.
Can a computer create this metadata for our business?
AI-powered tools support metadata creation, a time-consuming process that’s often one of the biggest pain points for DAM software administrators and users. As Image recognition software appeared in DAMs, we thought a real time-saver arrived for DAM-editors, a highly sought-after functionality - Auto-tagging of images.

What this functionality does, is that when uploading or organizing files in the media library, the administrator has the opportunity to activate an AI analysis of the images. The AI will analyze the images in question and suggest appropriate tags, that is, words or keywords, that describe the content of the image.
As the AI tagging is managed with the help of a cloud services, like Microsoft Cognitive Services among many others, the new functionality sends an image request to the cloud as a thumbnail picture of the original image, and the resulted suggested tags will be available in your image library database.
While the benefits of cloud-based software are plentiful, one question everyone has been asking is ‘where is my data going? A fair question in todays ePrivacy concerns.
While image recognition can also be deployed on-premise on your local servers, sensitive content doesn’t need to leave on-premises. This applies too for on-premises Video Analysis Server but both solutions come with a price tag. On-premise AI is mostly used in DAMs using custom models.
As we can use image recognition and image analysis for keywords and captions, we need to accept the consequences of also saving inadequate or even wrong metadata to the file. Tools like image recognition require a balance between automation and human touch. While it can free up time and resources for other value-driven projects, you are still needed to inform and guide both the technology and its users.
AI-generated metadata isn't working properly in DAM
The current AI tools used in DAM systems depend on statistical probability and pattern matching to generate keyword suggestions. Talking to data scientists it's enlightening to understand, that AI actually only delivers suggestions on what it can find from a ocean of pixels (digital image), but cannot extract easily contextual valid information.

All DAM vendors do always mention AI or autotagging in their marketing, but they rely on the above mentioned third-party components to deliver the limited form of it on offer. When DAM vendors present AI modules, they visualize the workflow by uploading a single, usually very generic image and the resulting keywords initially seem relevant.
When the technology is applied to the kind of real-world digital assets that populate a typical corporate DAM, the results become less satisfactory. In DAMs many business cases, this info is not really valid nor do descriptions and caption gain relevance in searchability.
Which metadata is needed in digital asset management depends on the origin data - and what should be done with it. What kind of metadata do you and your colleagues want to be able to search and filter by? Every company and every industry may require individual metadata types.
During 2017 we sold many image recognition solutions to our DAM customers. It was implemented in universities, public service and in real estate cases. Now in 2021, not one of them is in active use, because the promised aid in the time-consuming process of adding metadata did not give better search results, actually it deliverded less good search results. As a result the editor had to curate the automatic process by hand to mitigate false entries.
As a conclusion, computing can speed processes and reduces manual activity at its best, but it is still today at heart a human activity to curate the content, requiring ongoing decision making that only human insight can provide. Having said this, automated tagging seems not always a very helpful aid in automated data managment when applied with only generic models.
Photographers curation enhanced EyeEM models accuracy
One of the key difference in the EyeEm approach was that they had in the beginning a community of millions of users to add metadata and contextual data, teaching and confirming the computer vision model with a huge amount of accurate and non bias data per image. As the model was created human aided, and then teaches itself and learns along the road, the tagging accuracy results get even more impressing.
Today EyeEm focuses on delivering royalty-free stock images from a global creative community offering unique AI-assisted searches for users to find the most suitable images. For this service and its customers meaningful descriptions and aestethics values comes handy. This gives photographers exposure, and delivers the best content for Market buyers. It makes photos infinitely more discoverable from the moment they get uploaded.
EyeEm Vision imitates the curation expertise of professional photographers. Their deep learning technology unravels this expertise using a large collection of amazing photographs. EyeEM Vision uses Mobius Labs AI service today.
The autotagging problem lies in the relevance of suggested keywords
Either large numbers of assets have the same keywords, like fruit or shoe, diluting their relevance, or they are so vague and generic, like sun and people, that they're of little value. General autotagging tools are not designed for the job most DAM systems have to do. Too few tags and the images will never be discovered, too many generic terms and there’s the risk that the correct image gets drowned in an endless scroll of imperfect results.

Content moderating is often used by image recognition applications and can categorise the images as suitable for use. All tags are not needed in DAMs. In some DAM systems tags can automatically be added only if the words are relevant or chosen from a predefined list within the DAM, a black or white list. This helps the curation process and gives more value and accuracy to the result.
DAM users used to ask for AI features for their DAM, but today these features are mostly disabled or the AI generated metadata gets separated not to intrude in search results.
Unstructured datalike images need context to be found
Most DAM users aren't searching for generic assets that rely on non-contextual metadata. They care less that an image is of a round building against a blue sky, and more about whether it's their organization’s headquarters or not. The physical characteristics are subsidiary to the relevance of the subject. This context is the defining factor as to whether an asset's metadata will help or hinder you in finding it in your media library.
A dog is a dog, anyone can see that, but if the dog is running or eating, if its a retriever or if it belongs to something to separate it from other dogs, is important. By the way, creating an image recognition model is not anymore scifi, data scientist students create a model in no time. Critical is how accurate the model gets which depends on the amount of data and whether the data in non-biased.

AI technologies have a lot of potential but still leave room for improvement when it comes to accuracy and specificity. The basic service appears still too general or inexact, and the time spent cleaning up inaccuracies outweighs any potential time savings.
Today, image recognition technology is at a point where some of our clients may find its results useful. The next evolution is to make the technology more personalized for client's unique needs through contextual analysis, custom models and tags.
Applied new advanced AI closes the gap for accurate search results in DAMs in coming years
DAM vendors are working on additional features that will harness the power and functionality to take its digital asset management services to the next level. One of the functions is to create custom models within the DAM-system.
DAMs generally do not have enough data for a model to utilize an accurate tagging process, epecially if custom-made models are used. Some services argue that 10 images is enough for starters for creating custom concepts, but what the accuracy and quality concerns are in such a case, can be argued. The new models are much better than before, and therefore some few-shot learning models and concepts gain track.
Read more about new improved developments: DAM - AI is getting smarter
Check how Clarifai explains new AI platform at DAM Helsinki 2021
Advanced AI-assisted image and video search is the next content frontier using cognitive and contextual analysis. AI, computer vision, natural language processing, automated machine learning and OCR combined, is set to be one of the definitive evolutions of the future of digital asset management too. Algorithms are going to help you better take advantage of and describe content and adds value to digital content.
More corporates believe AI will allow their companies to obtain or sustain a competitive advantage.
 |
Author Rolf Koppatz Rolf is the CEO and consultant at Communication Pro with long experience in DAMs, Managing Visual Files, Marketing Portals, Content Hubs and Computer Vision. Contact me at LinkedIn. |